一、LangChain框架简介
1.1 LangChain的基本介绍
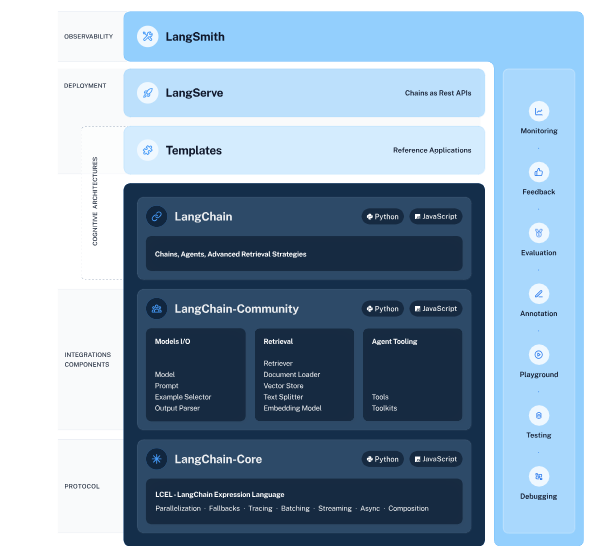
LangChain是一种专为大型语言模型(LLM)开发的应用框架。它通过模块化设计,简化了从开发到部署的整个流程。
LangChain在以下三个阶段提供支持:
- 开发:通过开源组件快速搭建应用,支持与第三方工具集成。
- 生产化:利用LangSmith进行链条的监控与优化,实现持续改进。
- 部署:通过LangServe将链条转化为API服务。
总结来说,LangChain通过标准化模块抽象,为LLM应用开发提供了强有力的支持。
1.2 核心模块详解
LangChain框架的核心模块包括:
- Model I/O:标准化输入输出接口,实现模型调用与返回格式化。
- Retrieval:支持外部数据检索,包括文档加载、切割和向量化。
- Chains:链条模块,用于连接多个模块协同工作。
- Memory:提供上下文记忆功能,用于管理会话历史。
- Agents:支持多种工具调用,适用于复杂任务执行。
- Callbacks:回调系统,用于日志记录、监控和流处理。
1.3 LangChain的特点
LangChain具备以下优势:
- 强大的大语言模型支持:适用于各种自然语言处理任务。
- PromptTemplates:支持通过模板轻松构建和管理输入提示。
- 链条设计:可将多个模型连接起来实现复杂目标。
- 灵活的Agent支持:可定制化执行多种任务。
1.4 LangChain解决的行业痛点
大语言模型的使用存在以下痛点:
- 模型使用规范差异较大,学习成本高。
- 模型知识更新滞后。
- 外部API调用能力有限。
- 输出结果不稳定,难以控制。
- 与私有化数据的连接方式复杂。
1.5 安装指南
通过以下命令安装LangChain:
pip install langchain二、基于LangChain的客服机器人实战
2.1 环境配置与依赖安装
以下为实战所需的依赖安装代码:
pip install pandas
pip install openpyxl
pip install langchain
pip install -U langchain-community
pip install sentence-transformers
pip install faiss-cpu
pip install pyjwt2.2 数据加载
使用财经类数据作为示例:
import pandas as pd
file_path = 'SmoothNLP专栏资讯数据集样本10k.xlsx'
data = pd.read_excel(file_path)[:50]
2.3 文档分割
通过逐行分割实现文档的结构化处理:
from langchain.schema import Document
documents = []
for index, row in data.iterrows():
document = Document(page_content=f"{row['title']}\n{row['content']}")
documents.append(document)
2.4 向量搜索
2.4.1 相似性搜索
利用HuggingFaceEmbeddings进行文档编码,并使用Faiss进行向量检索:
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
embeddings = HuggingFaceEmbeddings()
db = FAISS.from_documents(documents, embeddings)
query = "双11广告我应该怎么打?"
docs = db.similarity_search(query)
2.4.2 相似性分数检索
retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.8})
docs = retriever.get_relevant_documents("苏宁618")
for doc in docs:
print(doc.page_content)2.4.3 数据库存储与加载
存储和加载FAISS向量数据库的代码示例:
# 存储
db.save_local("real_estates_sale")
# 加载
db = FAISS.load_local("real_estates_sale", embeddings)2.4.4 数据库检索与LLM结合
将数据库检索与大模型结合,构建智能问答系统:
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatZhipuAI
llm = ChatZhipuAI(model="glm-4", temperature=0.5)
system_prompt = (
"Use the given context to answer the question. "
"If you don't know the answer, say you don't know. "
"Use three sentence maximum and keep the answer concise. "
"Context: {context}"
)
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}")
])
question_answer_chain = create_stuff_documents_chain(llm, prompt)
chain = create_retrieval_chain(db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.2}), question_answer_chain)
chain.invoke({"input": query})
通过以上步骤,您可以构建一个功能强大的客服机器人,既能高效检索知识库,又能通过大模型生成智能回答。

