简介
Azure AI 服务中的语音识别 API 是微软提供的一项先进技术,旨在帮助开发者轻松实现语音转文本的功能。它通过集成云端的强大计算能力,为各种应用场景提供高效、准确的语音识别解决方案。这一服务非常适合需要语音交互的应用,比如语音助手、智能客服以及实时字幕生成等。
语音识别 API 的功能十分强大,它能够将用户的语音输入快速转化为文字,并提供多种识别模式以适应不同场景。例如,在对话模式下,服务可以识别人与人之间的交流内容;在听写模式中,它支持更长时间的语音输入并生成完整文本;而在交互模式中,它可以快速处理简短请求,为用户提供即时反馈。这些功能使得开发者能够设计出更加智能化、便捷的应用程序。
为了让开发者更直观地了解语音识别 API 的效果,Azure 官方提供了一个语音识别的演示程序。在这个演示中,用户只需点击 “开始录音” 按钮并对着麦克风说话,系统即可自动将语音内容转换为文本并实时显示输出。这种简单易用的交互方式展现了语音识别技术的实用性和潜力。

创建 Azure 服务
要使用 Azure 的语音识别服务,首先需要在 Azure 平台上创建一个 Bing Speech API 服务实例。这是整个开发过程的第一步,也是至关重要的一步,因为所有后续的操作都依赖于这个服务实例的配置和授权。
Azure 为用户提供了免费的试用选项,这对学习和实践非常友好。如果您是刚接触 Azure 的新手,可以注册一个免费的 Azure 账号。在免费账户中,您可以使用基础版的 Bing Speech API 服务,这足够支持个人学习和开发实验。注册过程简单,只需填写基本信息并验证身份即可完成,随后便可以开始使用服务。
创建服务实例的具体步骤如下:
- 登录您的 Azure 账号并进入 Azure 管理门户。
- 点击“创建资源”,在搜索框中输入“Bing Speech API”。
- 选择对应的服务并点击“创建”,填写实例的相关信息,比如名称、订阅类型、资源组等。
- 完成设置后,点击“确认”,系统会自动为您创建服务实例。
服务实例创建完成后,您需要获取它的 key 信息。这些 key 是您调用 API 的必要认证凭据,确保只有授权的用户才能访问该服务。您可以通过以下步骤获取 key:
- 在 Azure 管理门户中,找到刚刚创建的 Bing Speech API 服务实例。
- 点击服务实例进入详情页面,在“Keys and Endpoint”选项中查看 key 信息。
- 复制这些 key 并安全保存,它们将在您的代码中用于身份验证。
总的来说,通过 Azure 创建 Bing Speech API 服务实例并获取 key 是一个简便的过程,但它为后续开发奠定了基础。如果您碰到任何问题,可以参考 Azure 官方提供的文档或社区支持。

开发 WPF 程序
在开发 Azure 语音识别服务的应用程序时,开发者可以选择使用 Bing Speech API 提供的两种主要方式:REST API 和客户端类库。这两种方式各有优点,具体选择取决于您的应用需求。REST API 适合轻量级的开发场景,通过简单的 HTTP 请求即可实现功能;而客户端类库则提供了更高效的开发体验,适合需要更复杂功能和性能优化的项目。
在这篇教程中,我们采用的是客户端类库进行开发。为了确保程序能够正常运行,开发者需要对工程的环境进行一定的设置。客户端类库提供了 x86 和 x64 两个版本,我们选择了 x64 的版本 Microsoft.ProjectOxford.SpeechRecognition-x64。因此,在 Visual Studio 中需要将工程的 platform target 设置为 x64,以匹配所使用的类库版本。具体步骤如下:
- 打开 Visual Studio,右键单击项目名称,选择“属性”。
- 在属性窗口中找到“Build”选项卡。
- 将“Platform target”设置为 x64,并保存设置。
除了环境配置之外,认证信息的定义也是开发中的重要环节。Azure 的所有认知服务,包括 Bing Speech API,都需要使用服务实例的 key 进行身份验证。这是为了确保只有经过授权的用户能够调用该服务。
在程序中,可以通过定义一个常量来保存 key 信息。例如:
const string SUBSCRIPTIONKEY = "your bing speech API key";将 key 定义为常量不仅便于管理,还可以避免在代码中重复使用硬编码的字符串,从而提高代码的可维护性。此外,为了确保安全性,建议将 key 存储在环境变量或配置文件中,而不是直接暴露在代码中。
通过上述步骤,开发者可以完成 WPF 项目的初始设置,为后续调用 Bing Speech API 和实现语音识别功能打下坚实的基础。
语音识别模式
在使用 Bing Speech API 进行语音识别时,了解并选择适合的识别模式至关重要。不同的应用场景需要配合不同的识别模式,以确保最佳的用户体验和识别效果。Azure 的语音识别服务提供了三种主要的识别模式:对话模式、听写模式和交互模式。
以下是这三种模式的详细介绍:
- 对话模式(Conversation Mode):此模式主要应用于人与人之间的语音交流场景。在对话模式中,语音识别服务会持续监听和处理多轮对话内容,适合用于会议记录、实时字幕生成等场景。
- 听写模式(Dictation Mode):听写模式适合用于较长的语音输入,它可以将一段连续的语音内容识别为完整的文本。这种模式通常应用于写作辅助工具,或者需要用户长时间讲话的场景,比如语音备忘录。
- 交互模式(Interactive Mode):交互模式的特点是处理简短的语音请求,并快速返回识别结果。它特别适合语音助手、智能家居控制等场景,用户可以通过简短的指令与设备交互。
在 Bing Speech API 中,不同的识别模式对应不同的枚举类型。开发者可以通过 SpeechRecognitionMode 枚举来选择适合的模式。该枚举包含两个主要选项:
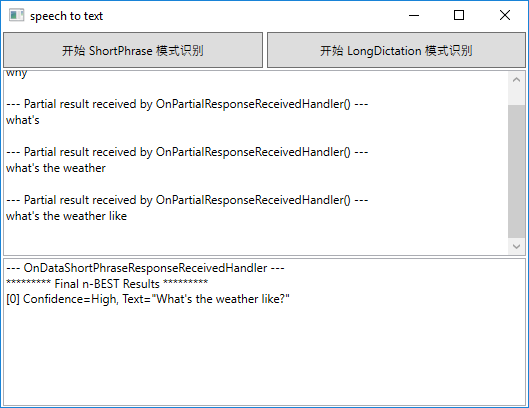
- ShortPhrase 模式:用于识别较短的语音输入(最长支持 15 秒)。它会返回多个部分结果和一个包含 n-best 选项的最终结果。
- LongDictation 模式:用于识别较长的语音输入(最长支持 2 分钟)。语音数据会被分块发送到服务器,服务端根据语句停顿返回多个最终结果。
开发者可以根据语音输入的长度和应用场景选择合适的模式。例如,在需要实时反馈的场景中,ShortPhrase 模式更为适合;而在需要处理连续语音内容时,LongDictation 模式则是更好的选择。
以下代码示例展示了如何使用 SpeechRecognitionMode 枚举来设置识别模式:
// 使用 ShortPhrase 模式创建语音识别客户端
this.dataClient = SpeechRecognitionServiceFactory.CreateDataClient(
SpeechRecognitionMode.ShortPhrase, // 指定识别模式为短语模式
"en-US", // 设置语音语言为英语
SUBSCRIPTIONKEY // 使用服务实例的 key
);
通过选择合适的语音识别模式,开发者可以更好地满足不同场景下的需求,从而提升应用的智能化程度。
分块传输音频
为了实现实时的语音识别效果,在使用 Bing Speech API 时,开发者需要将音频数据分块传输到服务器端。这种方法不仅能够减少延迟,还可以确保语音识别服务能够在接收到每一块数据时快速处理并返回部分结果,提升用户体验。
音频分块传输的核心在于将语音文件以固定大小的块连续发送给服务端。通过这种方式,服务端可以逐步接收数据并实时进行识别,而不是等待整个音频文件传输完成后再开始处理。以下是实现音频分块传输的代码示例和步骤说明:
- 初始化一个文件流,用于读取音频文件。
- 定义一个固定大小的缓冲区(例如 1024 字节)以存储每次读取的数据块。
- 循环读取音频文件的数据块,并通过语音识别客户端发送到服务端。
- 在数据传输完成后调用
EndAudio()方法,明确通知服务器数据已传输结束。
以下是具体的代码示例:
private void SendAudioHelper(string wavFileName)
{
using (FileStream fileStream = new FileStream(wavFileName, FileMode.Open, FileAccess.Read))
{
int bytesRead = 0;
byte[] buffer = new byte[1024]; // 定义缓冲区大小为 1024 字节
try
{
do
{
// 从音频文件中读取数据到缓冲区
bytesRead = fileStream.Read(buffer, 0, buffer.Length);
// 将缓冲区的数据发送到服务端
this.dataClient.SendAudio(buffer, bytesRead);
} while (bytesRead > 0);
}
finally
{
// 通知服务端音频数据传输已完成
this.dataClient.EndAudio();
}
}
}
在上述代码中,SendAudioHelper 方法负责打开音频文件并将数据逐块发送给服务器。通过 dataClient.SendAudio 方法,音频数据可以实时传输到服务端进行处理。而在传输结束时调用 EndAudio() 方法,确保服务端能够正确结束识别过程并返回最终结果。
分块传输音频的好处在于可以实现近乎实时的语音识别效果。用户的语音内容在每次传输一个数据块后即可获得部分识别结果,这种实时性非常适合需要即时反馈的场景,例如语音助手或在线翻译工具。
部分结果与最终结果
在使用 Bing Speech API 进行语音识别时,系统会生成两种类型的识别结果:部分结果和最终结果。这种结果的划分不仅能够提升实时性,还能帮助用户在语音输入过程中获得即时反馈。
部分结果:
部分结果是系统在处理语音数据时实时生成的中间识别结果。通过 OnPartialResponseReceived 事件,客户端可以接收到这些实时的部分结果,并将其展示给用户。这种即时性非常适合语音助手或实时字幕等场景,能够让用户感受到更流畅的交互体验。以下是部分结果的示例:
--- Partial result received by OnPartialResponseReceivedHandler() ---
why
--- Partial result received by OnPartialResponseReceivedHandler() ---
what's
--- Partial result received by OnPartialResponseReceivedHandler() ---
what's the weather
--- Partial result received by OnPartialResponseReceivedHandler() ---
what's the weather like
从这个示例中可以看到,识别结果会随着语音输入的增加逐步变得更加完整。每次 OnPartialResponseReceived 事件被触发时,系统会更新识别结果,将其展示给用户,提供一种近乎实时的体验。
最终结果:
最终结果是系统在语音输入结束后生成的完整识别结果。通过 OnResponseReceived 事件,客户端可以接收到最终结果,并展示给用户。最终结果通常包含 n-best 列表,即多个识别选项,每个选项都带有置信度值(Confidence),用来表示系统对该识别结果的准确性估计。例如:
--- OnDataShortPhraseResponseReceivedHandler ---
********* Final n-BEST Results *********
[0] Confidence=High, Text="What's the weather like?"
从示例中可以看到,最终结果以 n-best 列表的形式返回,列表中的每个选项包含以下属性:
- Confidence:表示系统对该识别结果的置信度,通常可以帮助开发者判断结果的可靠性。
- Text:识别的文本内容,是用户输入语音的最终转化结果。
在实际应用中,开发者可以根据置信度选择最优的识别结果,或向用户展示多个选项供其确认。这种方式尤其适合需要高准确度的场景,例如语音输入法或专业领域的语音识别。
部分结果和最终结果的结合使用,可以满足实时反馈和准确性兼备的需求。部分结果提升了交互的流畅性,而最终结果确保了识别的完整性和可靠性。
支持语言
Bing Speech API 是一个功能强大的语音识别服务,它支持多种语言的识别,包括中文。对于中文用户来说,这项服务的强大支持使其能够轻松应用于多种场景,例如智能语音助手、语音输入法以及语言学习工具等。
在 Bing Speech API 的支持语言列表中,中文(包括普通话和粤语)已经实现了全面支持,这意味着开发者可以通过该服务准确地识别中文语音内容。这对于中文用户群体来说是一个巨大的优势,尤其是在需要处理本地化语音数据的应用中。
如果开发者需要了解 Bing Speech API 所支持的所有语言,可以参考微软提供的官方文档。该文档详细列出了每种语言的支持情况,包括语音识别模式和功能范围。开发者可以通过以下链接访问支持语言的完整列表:
在本教程的演示中,为了简化操作和测试,我们使用了英语语音作为 demo 数据。英语的识别效果非常优秀,尤其是微软提供的高质量语言模型能够在发音标准的情况下实现精准的识别。当然,开发者完全可以选择中文或其他语言作为测试数据,根据自己的项目需求进行调整。
以下是演示中使用的英语语音识别示例:
通过 Bing Speech API 对多语言的支持,开发者可以轻松构建全球化的应用,同时也能满足本地化的独特需求。无论是中文还是其他语言,微软的语音识别服务都能够为开发者提供强大的技术支持。
总结
语音识别技术的发展历程可以追溯到数十年前。在早期,语音识别技术主要依赖基于规则的方法,要求用户反复训练系统以适应个人的声音特征。这种方法效率低下且识别效果有限,但当时的技术已经让人们对语音识别的潜力充满了期待。随着计算能力的提升和算法的进步,语音识别技术逐渐从基于规则转向统计模型,再到如今的深度学习驱动的人工智能技术。
近年来,语音识别与人工智能的结合为技术发展带来了新的希望。得益于深度学习算法和海量数据的支持,现代语音识别技术已经能够实现高准确度,甚至在嘈杂环境下也能识别出用户的语音内容。像 Azure 的 Bing Speech API 这样的服务,不仅能够快速转化语音为文本,还能提供实时反馈和多语言支持,为开发者提供了强大的工具来构建智能化应用。
然而,语音识别仅仅是人工智能领域的一部分。更深层次的挑战在于如何让 AI 理解文本的含义。这意味着不仅要识别用户说了什么,还需要理解他们的意图。例如,语音助手需要根据用户的语音指令执行具体任务,而不是简单地转化语音为文字。这种能力涉及自然语言处理(NLP)领域的发展,结合语音识别和文本理解的技术将是未来 AI 应用的关键。
展望未来,语音识别技术将继续与 AI 的其他领域深度融合,为人类带来更加智能的交互体验。无论是个人工具还是商业应用,这些技术都将在提升效率和用户体验方面发挥重要作用。
作为开发者,我们不仅应关注语音识别的实现,更要探索 AI 如何更好地理解文本内容,推动这一技术应用到更多实际场景中。

